
코딩하는 바나나
[VGGNet] Very Deep Convolutional Networks For Large-Scale Image Recognition 본문
[VGGNet] Very Deep Convolutional Networks For Large-Scale Image Recognition
유기농바나나칩 2023. 1. 28. 14:25VGGNet 은 옥스포드 대학에서 개발된 모델로 2014년 ILSVRC에서 2위를 차지한 CNN을 기반으로 한 딥러닝 모델이다.
Introduction
VGGNet은 CNN을 기반으로 하였기 때문에 CNN과 마찬가지로 크게 Convolutional layer, pooling layer, Fully connected layer 이렇게 3가지의 layer들로 구성된다.
그러나 VGG 이전의 ILSVRC에서 높은 순위를 차지한 모델들과는 다르게 CNN 모델의 depth 즉, 깊이에 중점을 둔다. 이전의 모델들은 주로 큰 receptive field (필터 크기)를 사용했지만 VGG에서는 모델을 더 깊게 설계하기 위해 아주 작은 receptive field (3 * 3)를 사용한다.
이렇게 작은 필터 크기를 사용하면 이미지 데이터가 조금씩 줄어들기 때문에 더 깊게 모델을 설계 할 수 있게된다.
VGGNet은 이렇게 깊은 CNN 모델을 설계하여 더 좋은 성능을 발휘한다.
Configuration
먼저 논문에서 사용한 VGG 모델의 전체적인 configuration을 살펴보자.
논문에서는 VGGNet의 깊이의 중요성을 비교하기 위해 여러개의 깊이가 서로 다른 모델을 비교한다.
먼저 VGGNet의 인풋으로는 224 X 224 RGB 이미지를 사용하였다.
전처리의 경우 각 픽셀의 RGB의 평균값을 뺴주기만한다.
receptive field의 크기는 앞서 나온 것과 같이 3X3을 사용한다.
여기서 드는 의문은 1X1이 제일 작은데 왜 3X3을 사용하는 지이다. 논문에서는 3X3이 상하좌우 방향의 의미를 가질 수 있는 가장 작은 크기이기 때문이라고 설명한다. 논문에서 사용되는 모델 중 하나는 1X1크기의 필터를 부분적으로 사용하는 모델도 있다.
그리고 Convolutional stride의 크기는 1로 고정된다.
pooling의 경우 max pooling이 사용되며 팔터의 크기는 2X2, stride의 크기는 2를 사용한다.
Convolutional Layer를 지나 마지막에는 3개의 Fully Connected layer를 지나게된다.
처음 두개의 layer는 4096개의 채널을 가지며 마지막 layer는 ILSVRC 데이터셋의 classification 개수인 1000개의 채널을 가진다.
여기서 모든 hidden later는 Relu를 사용하게된다.
LRN (정규화 방법)은 ILSVRC 데이터 셋에서의 성능에 영향을 미치지 않는 것을 알게되어 사용하지 않는다고 한다.

사실 큰 receptive field를 사용하는 것과 VGGNet의 작은 receptive field 여러개를 사용하는 것은 같은 효과를 가진다.
예를 들어 NXN 크기의 이미지에 7X7크기의 receptive field 사용하면 이미지의 크기는 N-7+1 즉, N-6 X N-6이 된다. NXN 이미지에 3X3 크기의 receptive field를 3번 사용하면 이미지의 크기는 ((N-3+1)-3+1)-3+1 즉, N-6 X N-6으로 똑같은 결과가 나온다. 그렇다면 3X3 크기의 receptive field 여러번 사용해서 얻을 수 있는 것은 무엇일까.
먼저, 하나의 receptive field를 사용할 때 보다 더 많은 non-linear 함수가 사용되기 때문에 non linear 한 문제들을 더 잘 풀 수 있게 되는 효과가 있다.
또한, 파라미터의 개수가 더 적어진다. receptive field의 인풋,아웃풋 채널의 크기가 C로 같다고 하면 7X7의 파라미터의 개수는 49C^2 3X3은 27C^2이다.
파라미터의 개수가 적어지므로 overfitting을 방지 할 수 있다.
Training
Training에서는 batch size 256, L2 regularization = 0.0005, 첫 두개의 fc layer에만 dropout rate = 0.5을 적용했고
learning rate = 0.01 에서 validation accuracy가 더 이상 개선되지 않으면 10씩 나누었다.
initialization의 경우 처음 4개의 layer와 마지막 3개의 layer에 A를 학습시킨 weight를 적용하였다.
나머지 layer의 경우 random initiliaztion 평균 0, 분산 0.01이 되는 정규 분포 weight를 사용했다.
Training set은 224X224 사이즈이기 때문에 rescale, random crop 사용.
Training set의 증강을 위해 random horizontal flipping, random RGB color shift 사용했다.
이미지 크기의 경우 두가지 방식이 있다. single-scale, multi-scale
single-scale은 고정된 하나의 크기로 이미지를 isotropically-rescale 하는 것이다. isotropically rescale은 이미지의 비율은 유지하며 이미지의 크기를 바꾸는 것을 의미한다.
논문에서는 isotropically-rescaled 이미지의 짧은 쪽 사이드의 길이를 S라 정의하고 S=256, S=384로 실험을 진행하였다.
multi-scale은 S의 크기를 고정하지 않고 일정 범위만 정해주는 것이다. 이런 기법은 scale jittering이라고도 불린다.
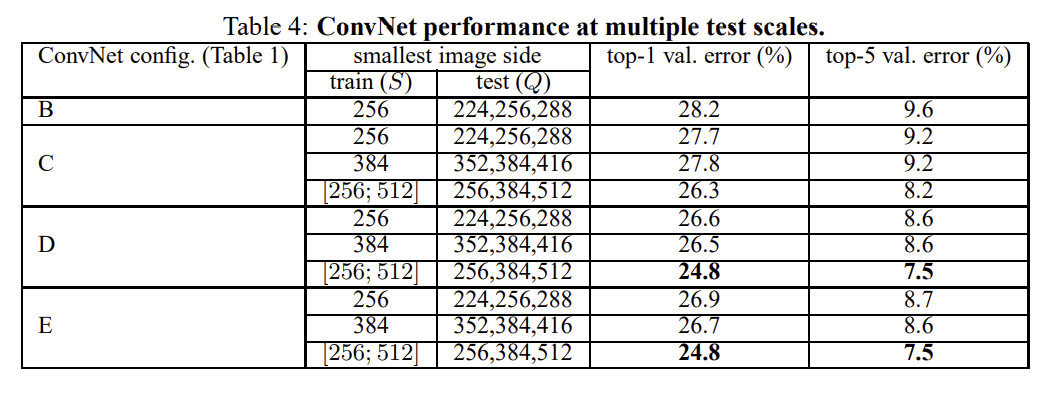
Testing
Test set의 경우 training 에서 사용했던 S의 값과 꼭 같은 값을 사용하지는 않는다. test 에서도 마찬가지로 single-scale로 test할 수 도 있고, multi-scale을 사용하여 test 할 수 도있다.
그리고 test시 사용하는 이미지는 crop을 하지 않고 사용하기 위해 조금 다른 구조의 CNN을 사용한다고 한다. 이는 오버피팅을 막기위함이다.
testing 에서는 vgg모델의 마지막 fully connected layer에서 첫번째 layer를 7X7 conv layer로 바꾸고 마지막 두개의 layer는 1X1 layer로 바꾼다. 이를 통과한 이미지는 1X1의 벡터로 표현이 될 것이다. 이미지의 크기가 다른 경우 다른 더 큰 벡터가 나올 수 있는데 이때 pooling을 통해 1X1 크기의 벡터로 만들어주게 된다. 이렇게 해서 이미지를 crop하지 않고 test를 진행 할 수 있다.
crop 없이 test를 진행하면 crop을 위한 계산을 할 필요가 없다는 장점이 있다.
그런데 crop을 진행하여 test를 하게되면 accuracy의 향상을 얻을 수 있다. 왜냐하면 crop을 해서 더 나은 샘플을 얻을 수 있기 때문이다.
논문에서는 이 두가지 방법과 두가지 방법을 합친 방법을 뒤에서 비교한다.


Ensemble
위의 결과들은 한개의 모델로만 얻은 정확도이다. 이 모델들을 앙상블을 통해 함께 사용한다면 정확도가 더 올라 갈 것이다. 논문에서는 가장 정확도가 높은 모델 D,E를 앙상블 하였을 경우 가장 좋은 결과를 얻었다고 말한다.

'Computer Vison' 카테고리의 다른 글
| [ResNet] Deep Residual Learning for Image Recognition (0) | 2023.02.01 |
|---|
